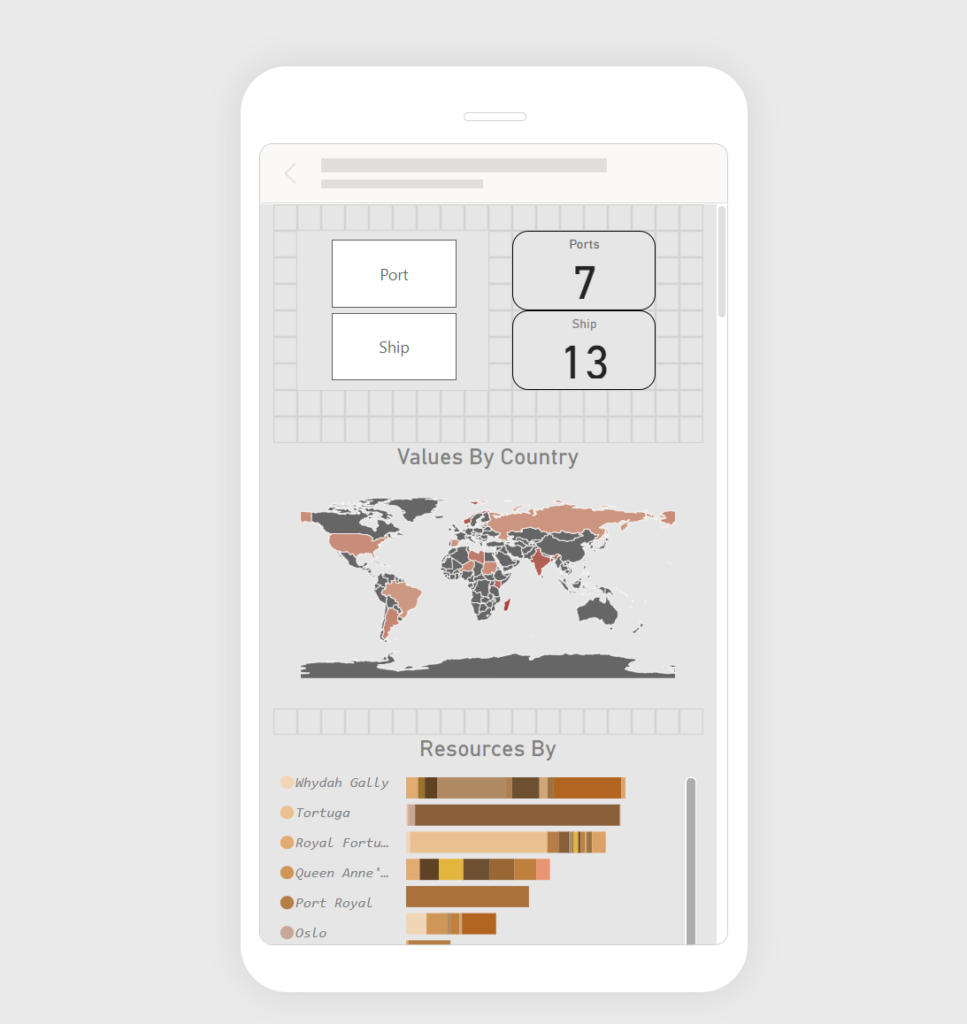
Badges to claim:
- Nasty Hacker – for retrieving data from 3rd party services and syncing it to the blob storage to connect to Azure AI Studio
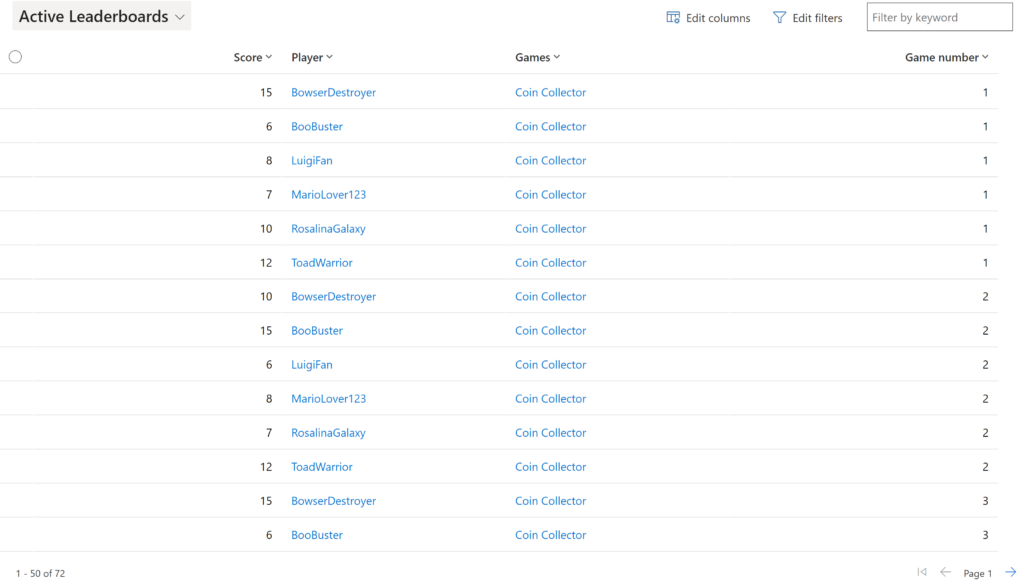
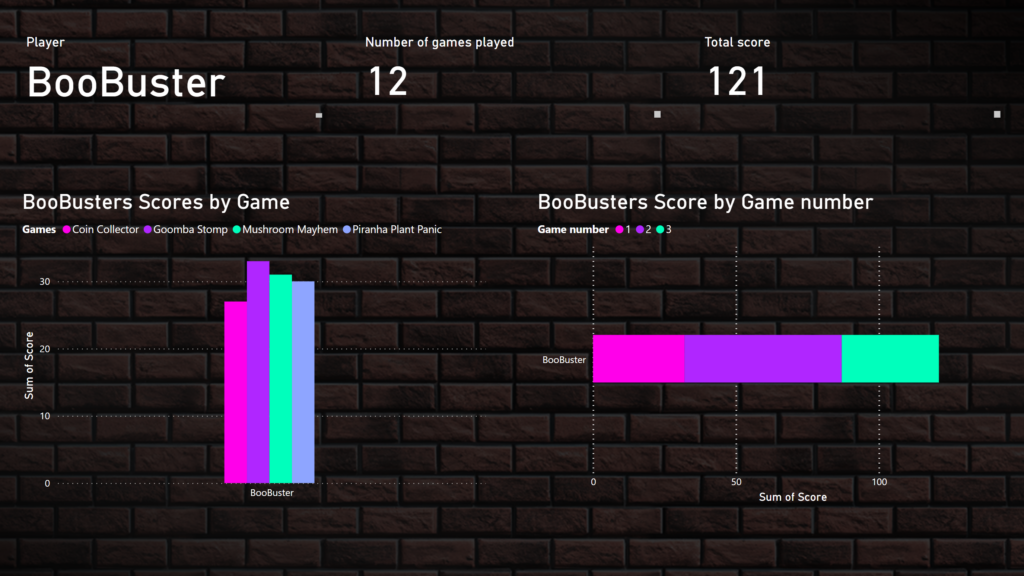
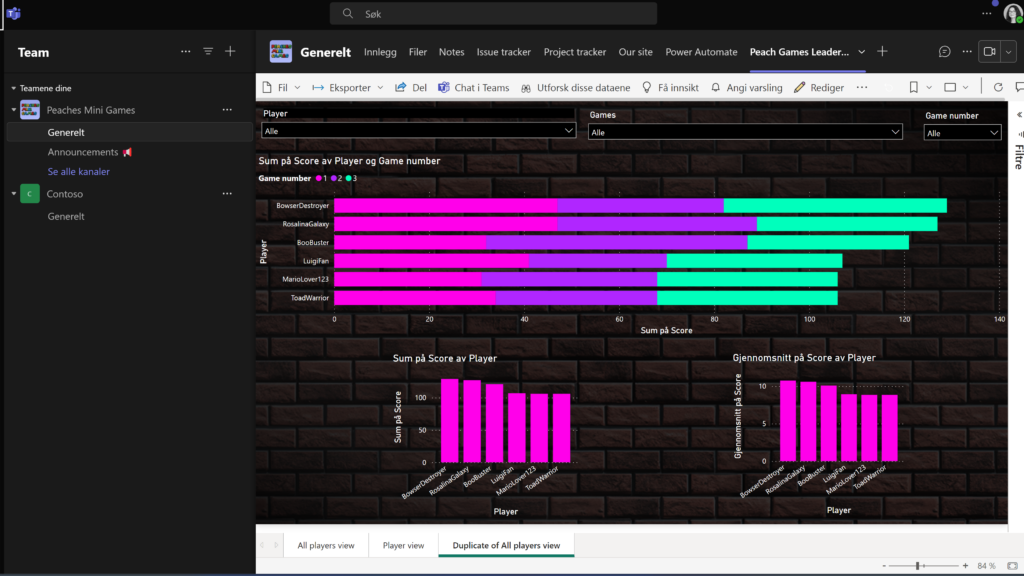
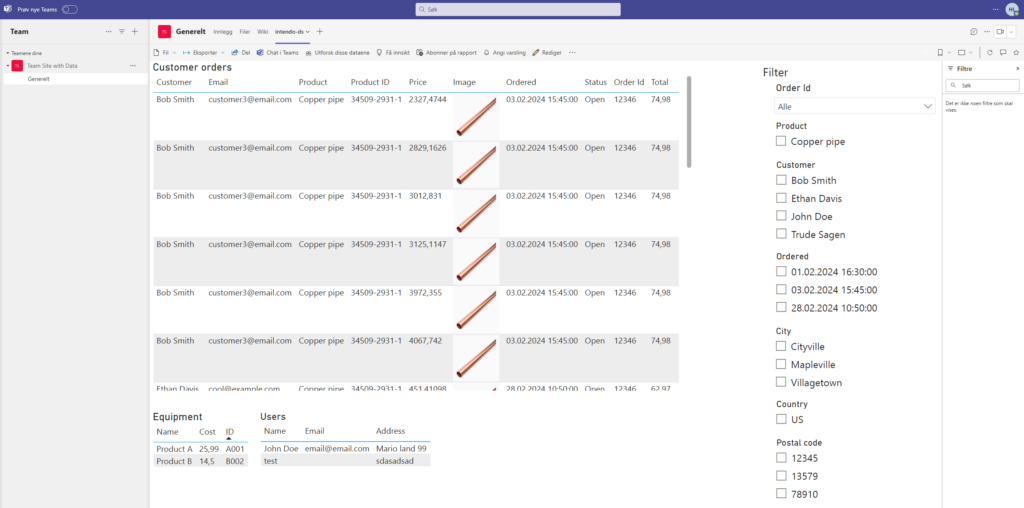
- Data miner – for retrieving the case information from dataverse and calculating the average score using AI.
- Embedding numbnut – for embedded copilot in Model-driven app
- Stairway to heaven – for using Azure AI Studio, Copilot, Blob storage, and in previous articles also Azure Function, WebApp

Our solution includes the latest features of the PowerPlatform and Azure connection the Low and Pro code approaches together, to allows you to boost the performance of resolving the cases by using some insights from the Copilot.
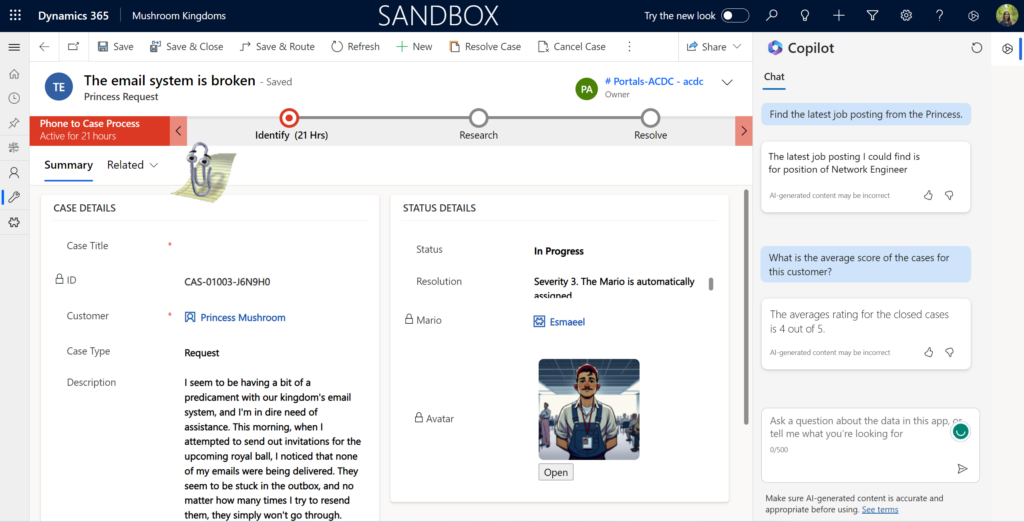
- The business use case is about complicated cases when we need external consultancy and assistant, so task is to find the suitable Marios-consultants according to the customer request, by searching the professionals on the Indeed, comparing their background and experience and finding the best matches. (to find the suitable Marios according to the request.)
- The business use case is about simplify the KYC(Know Your Customer) process by using unified workspace for all operations. From Indeed we can understand the company background,do semantic analysis of the comments to have insights on how technicians can approach customer (princess) (simplify the KYC(Know Your Customer) process by using unified workspace for all operations.)
- The business use case is about analyzing current princess (customer) and her needs based on the Indeed. The data that we were able to retrieve contains open job postings, company in for, recent news and personal profile info. Based on this information, we can suggest more other services and provide information to sales and marketing departments. (analyze current princess and her needs based on the Indeed profile and suggest more other services.)
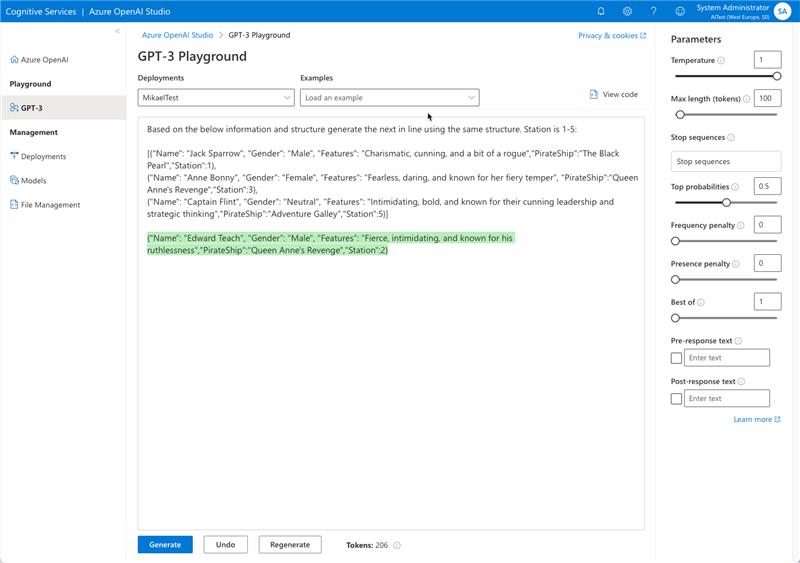
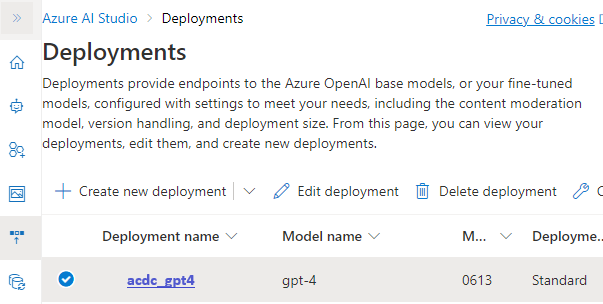
We deployed GPT-4 model to our personal instance using AI Studio, then fine-tuned it with company’s internal data and data from open sources like Indeed, Glassdor or proff.no.
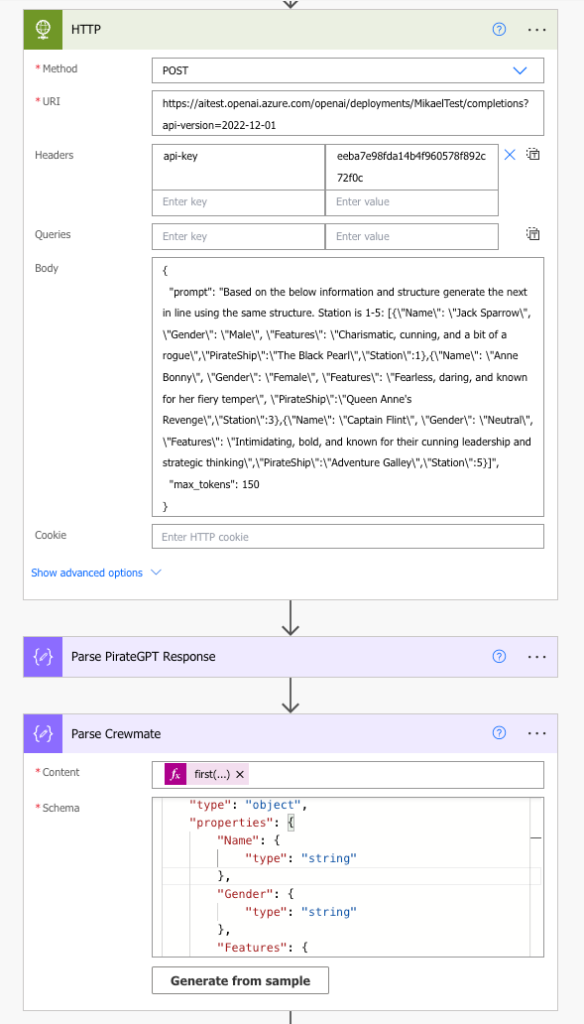
Than using Retrieval Augmented Generation (RAG) technic to inject generative responses from big LLM into answer of Copilot.
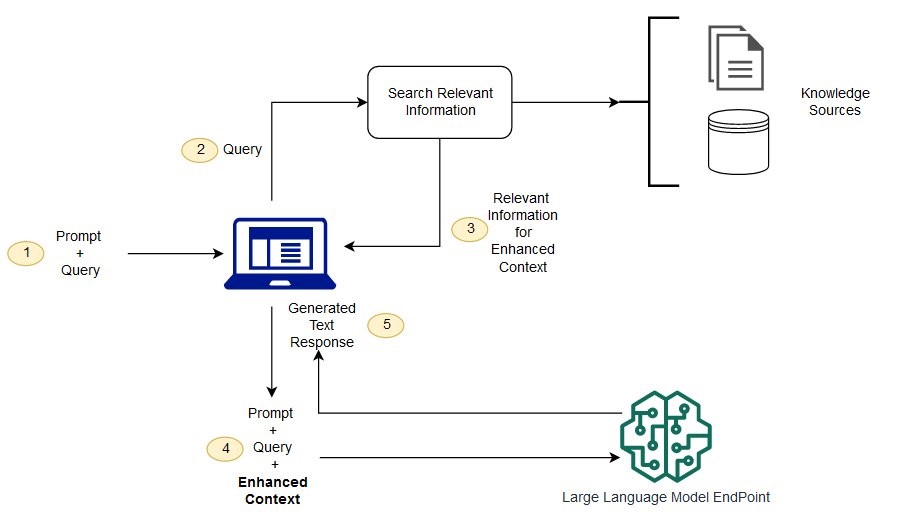
With RAG, the external data used to augment your prompts can come from multiple data sources, such as a document repositories, databases, or APIs. The first step is to convert your documents and any user queries into a compatible format to perform relevancy search. To make the formats compatible, a document collection, or knowledge library, and user-submitted queries are converted to numerical representations using embedding language models. Embedding is the process by which text is given numerical representation in a vector space.
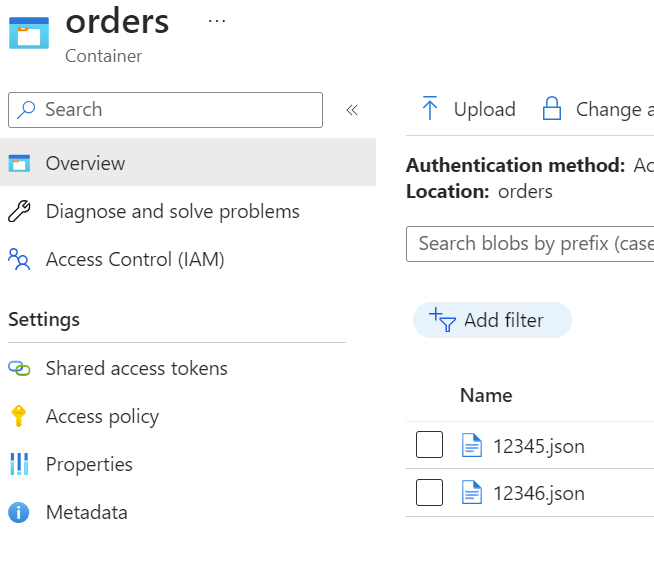
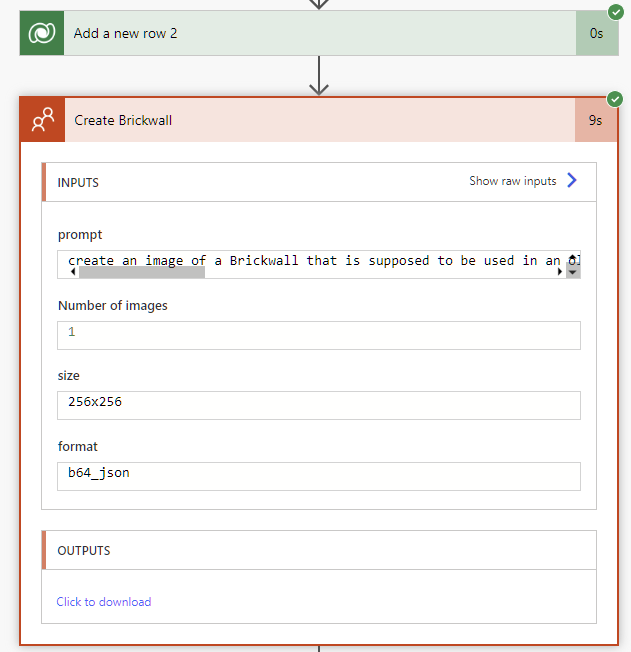
AI Studio has seamless integrated feature use Azure Blob Indexer to implement search functionality search for AI. It bring the possibility to simplify the access to the Datalake from LLM side.
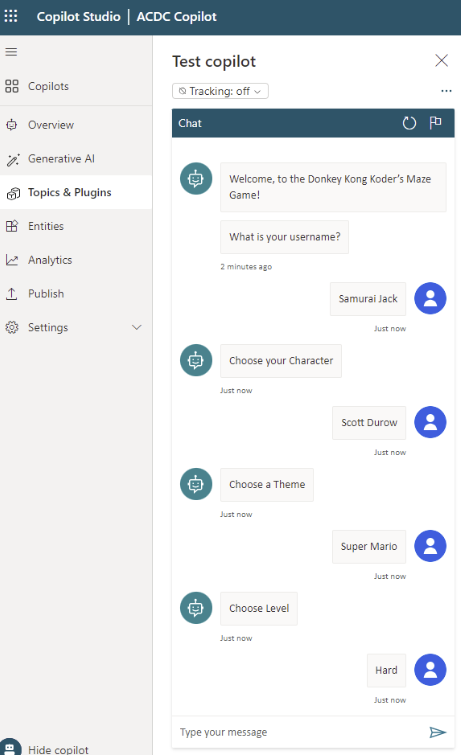
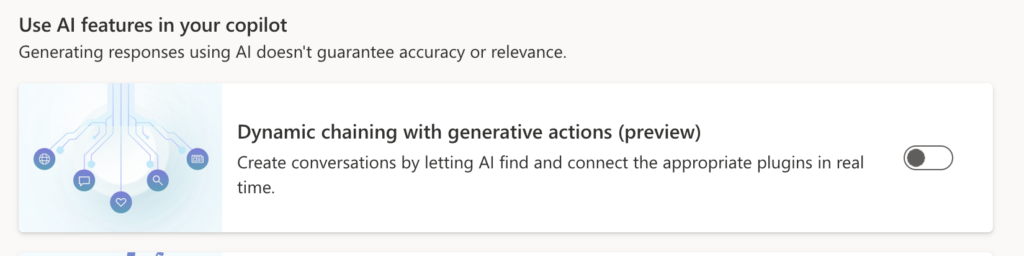
By implementing multiple connectors to the third-party services and data sources, together with Dynamic chaining feature of the Copilot it gives cleaner user experience for the user using only one tool for analyses.
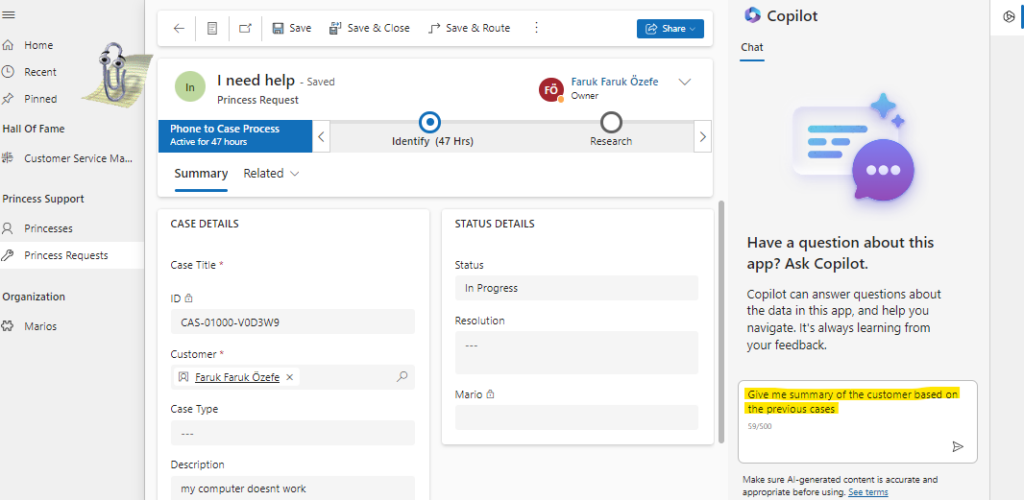
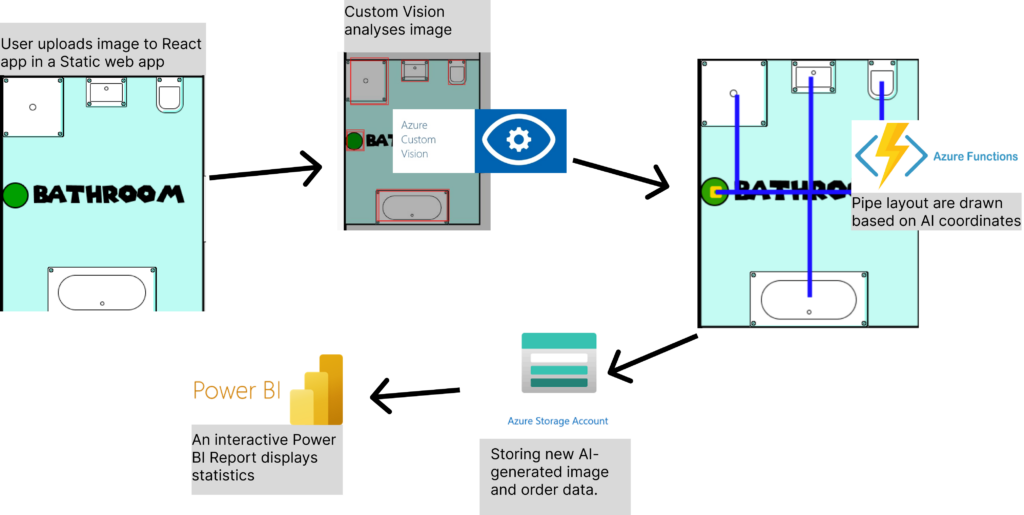
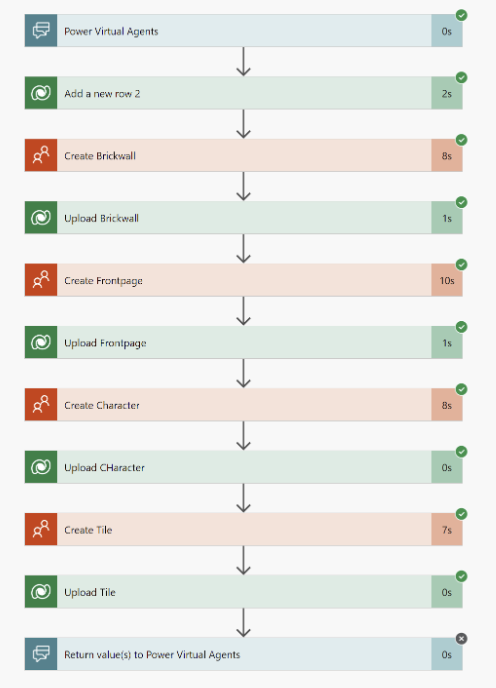
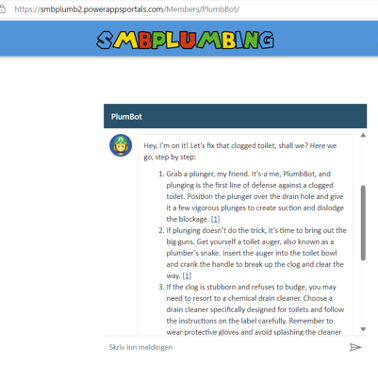
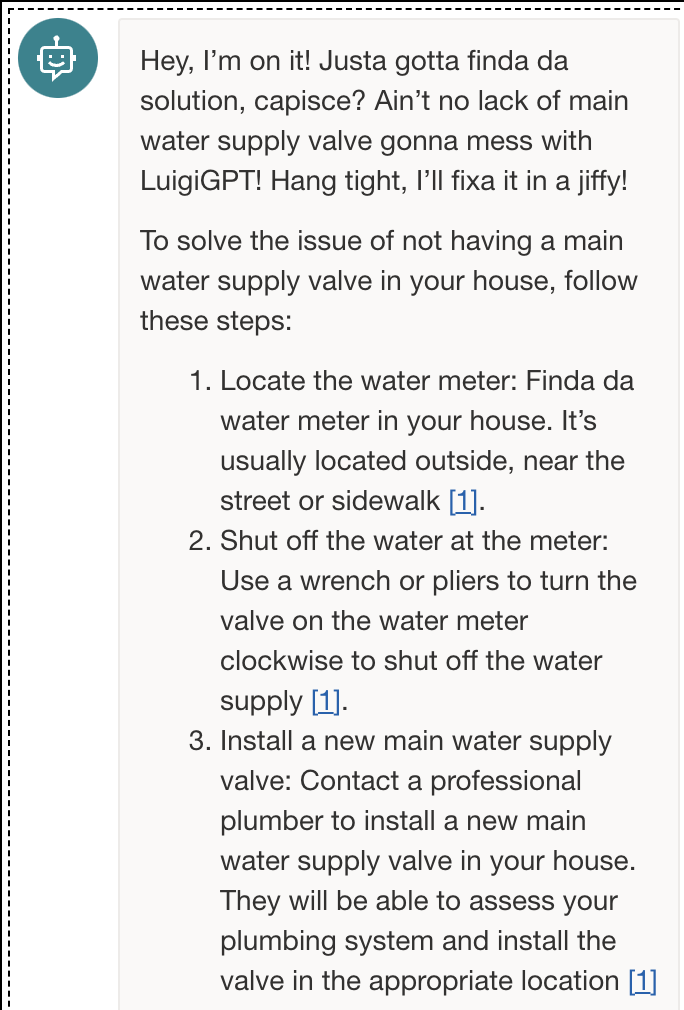
How it works: