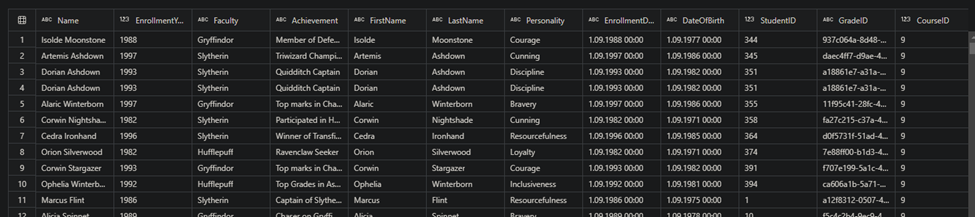
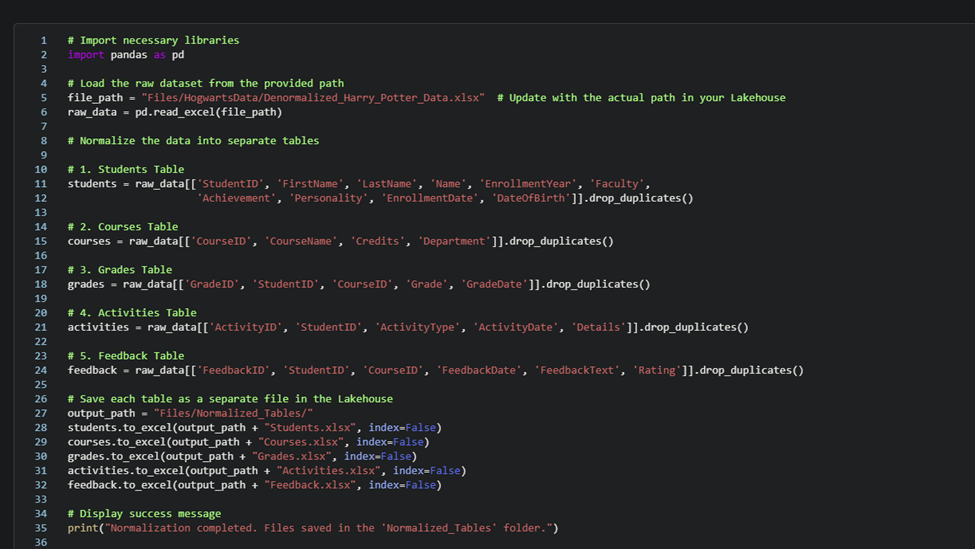
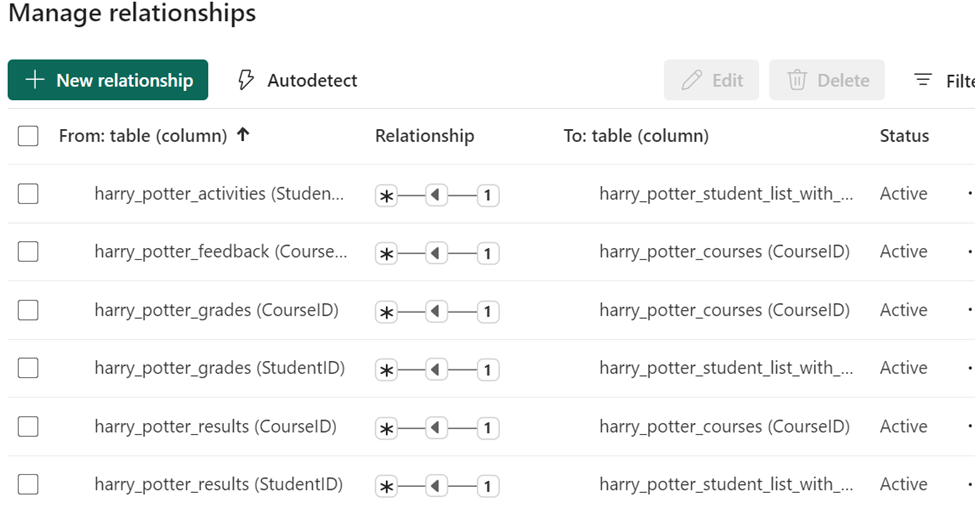
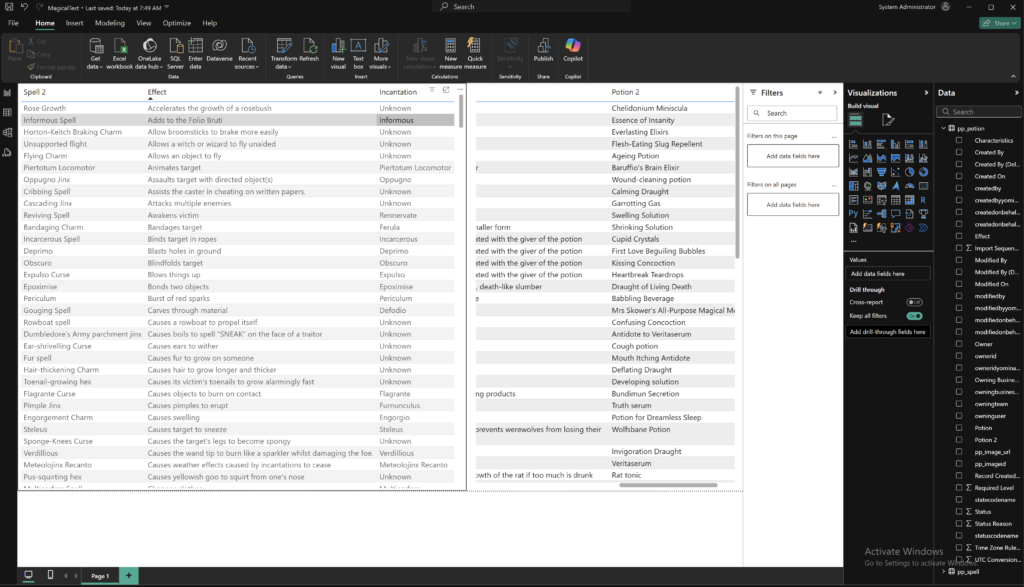
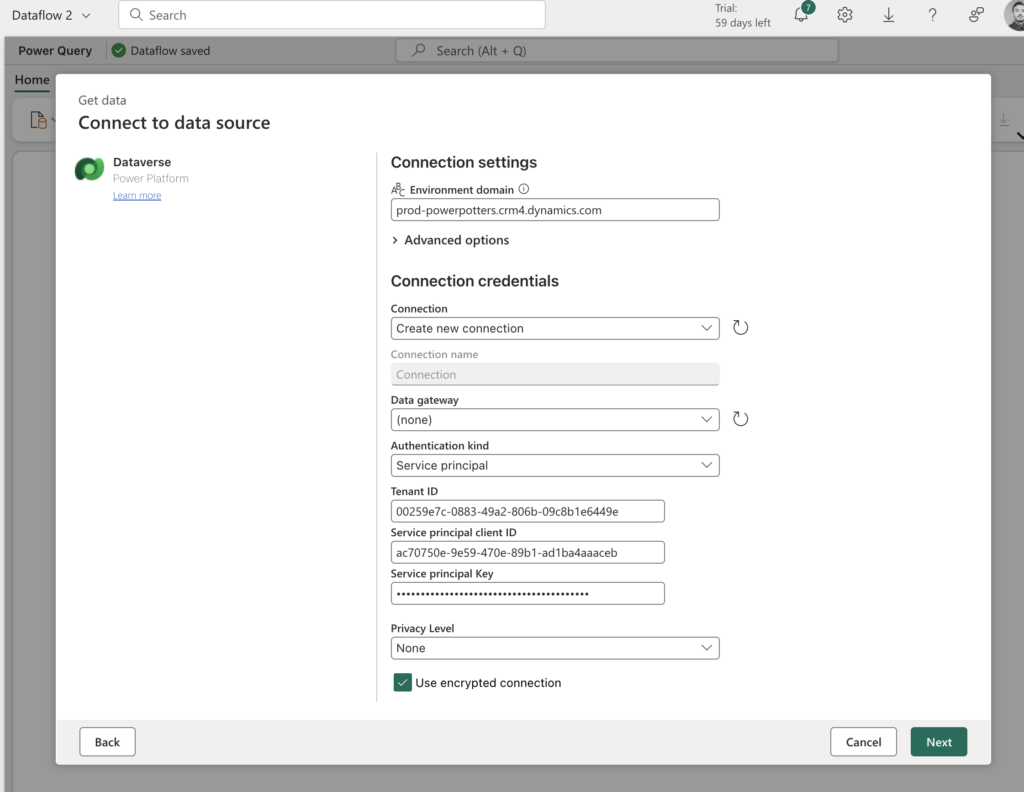
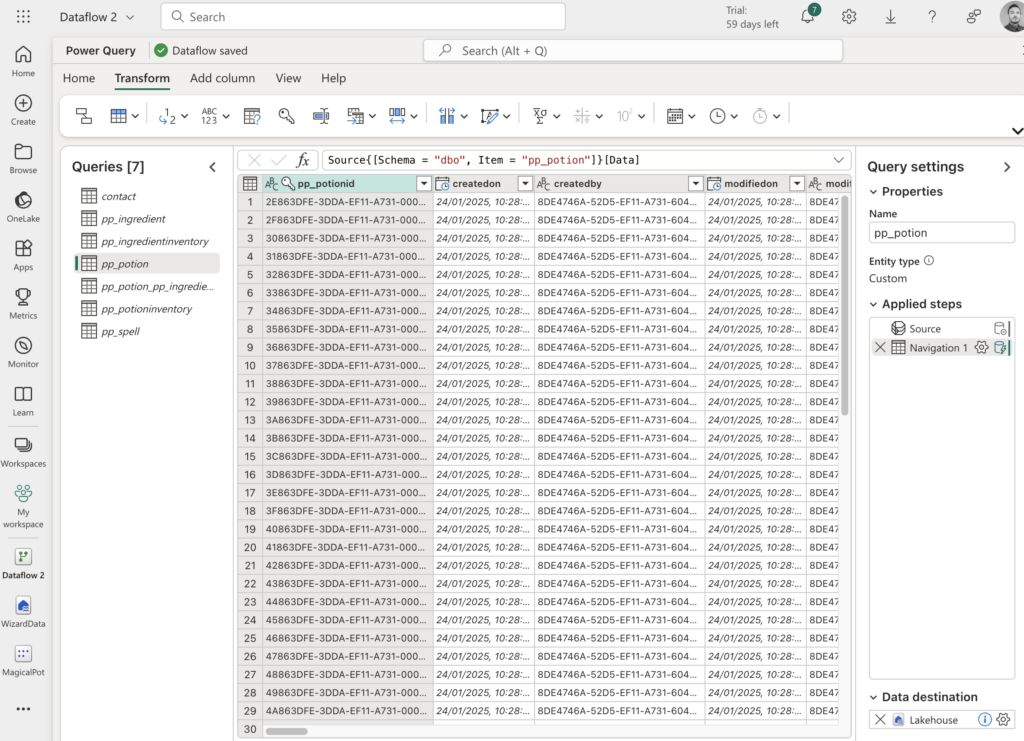
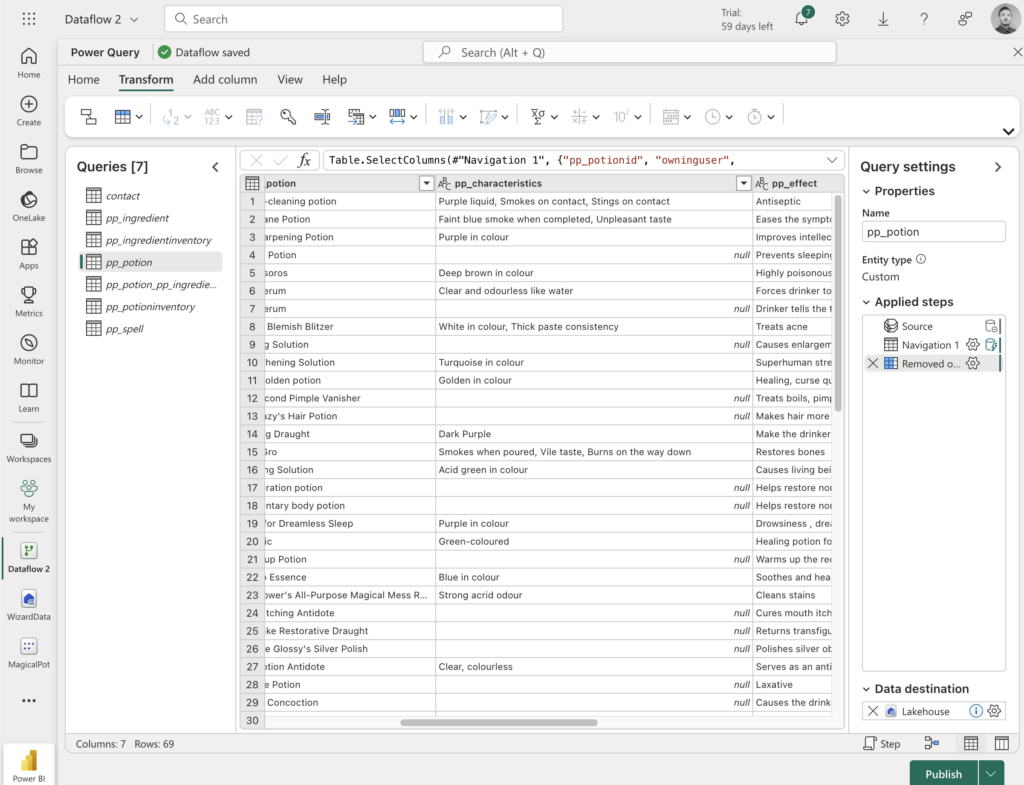
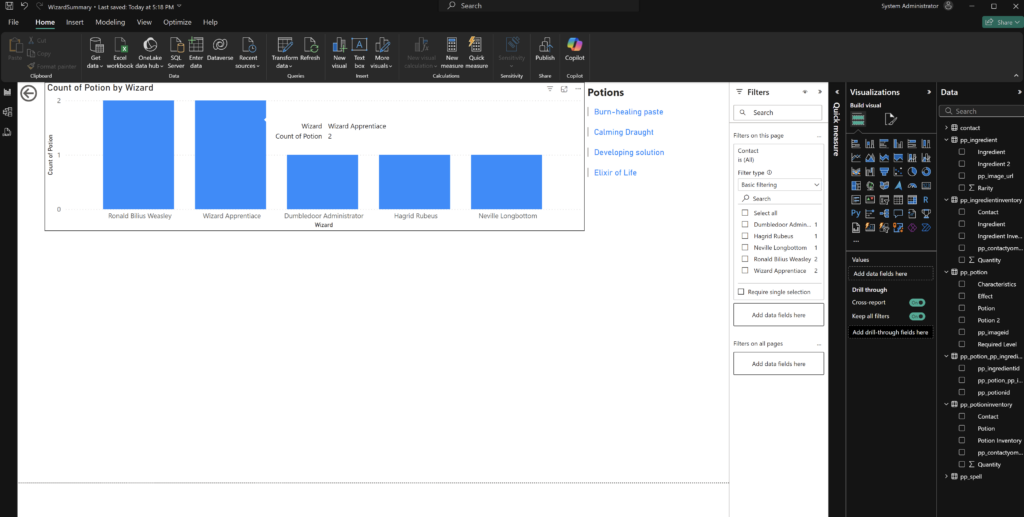
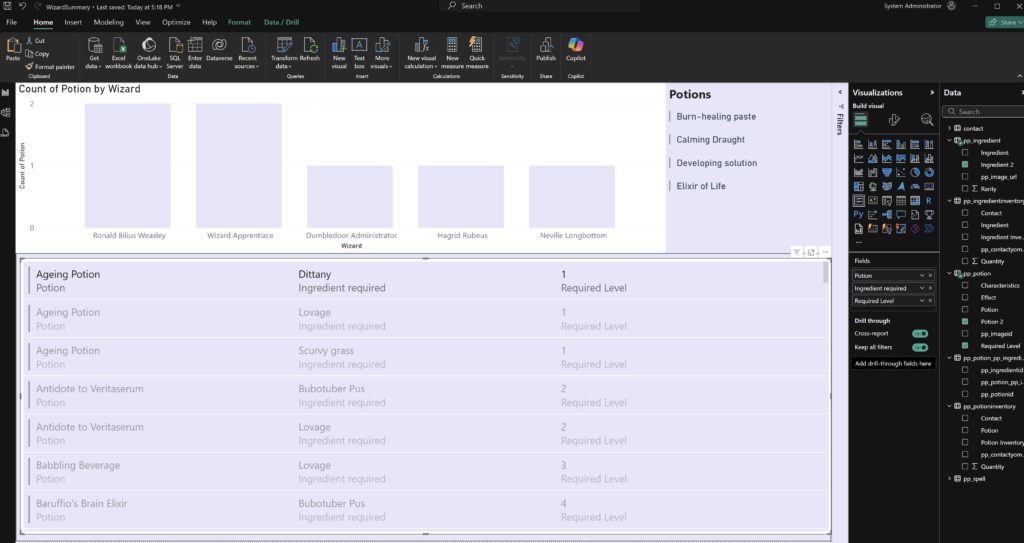
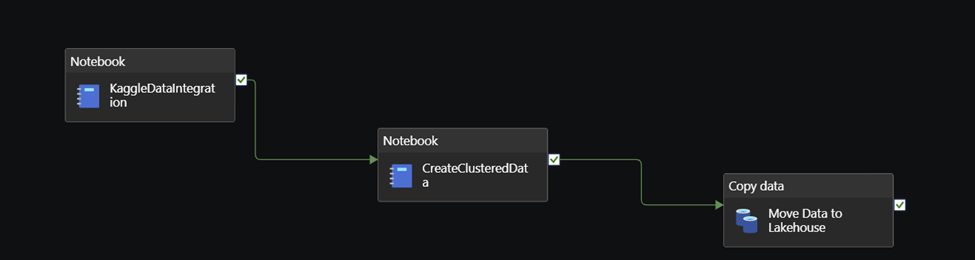
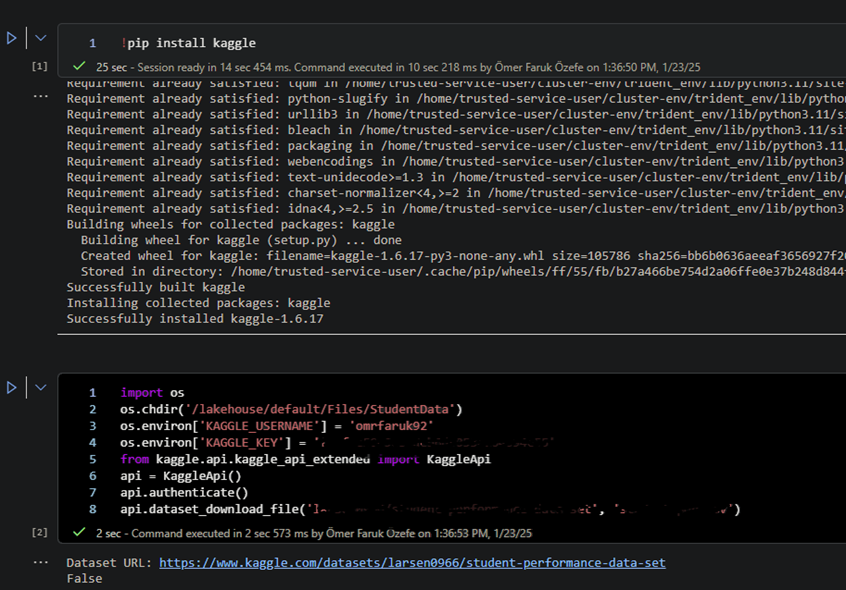
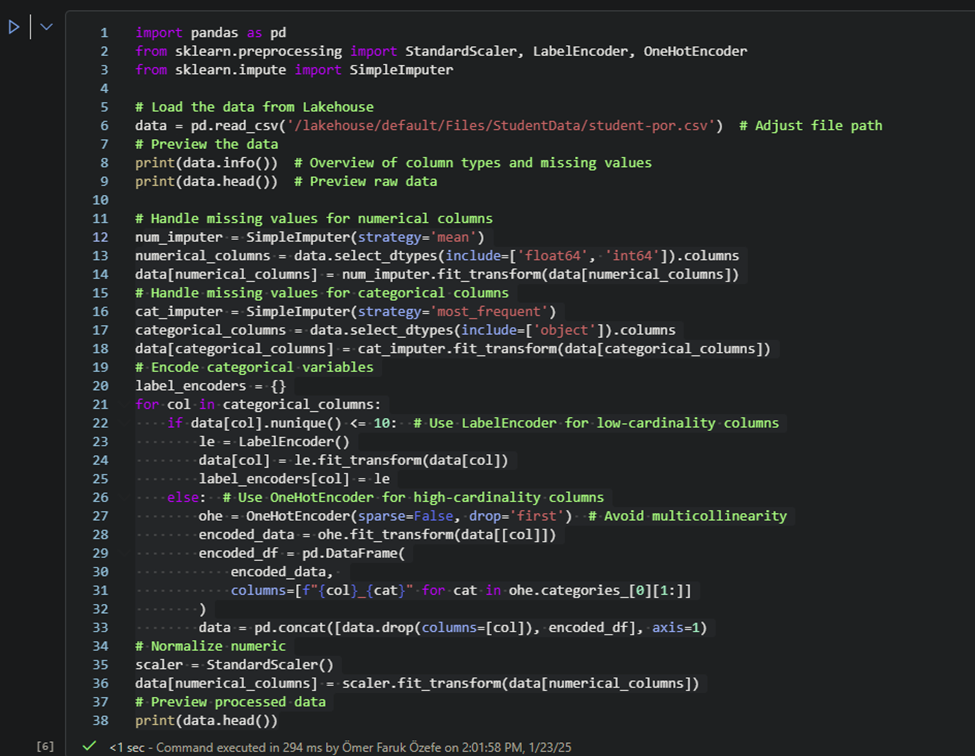
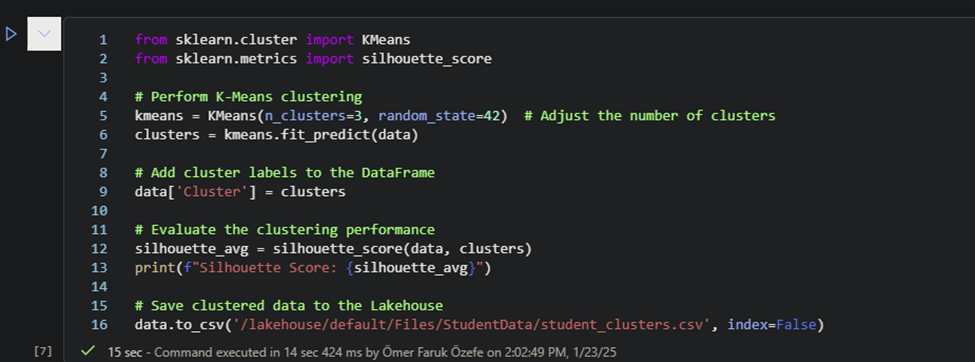
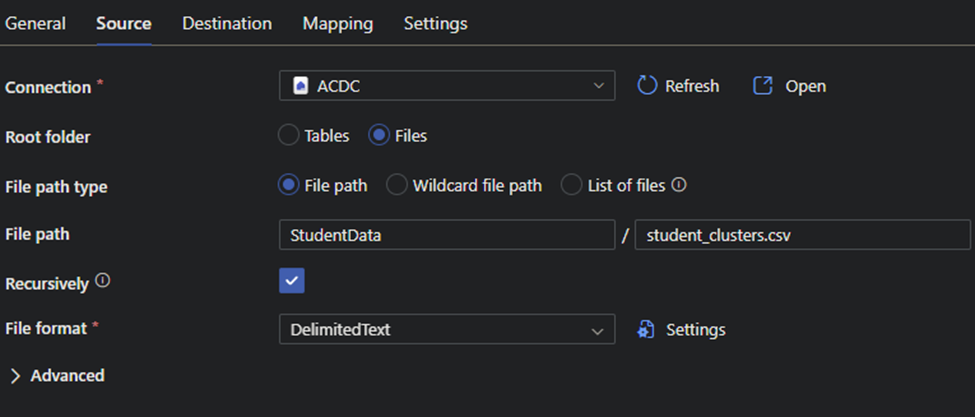
Any person can run power automate flows from dataverse. But only the Fabricator can trigger them from fabric lakehouse data changes using data activator in workspace.
Here we combined the power of fabric with flexibility of power automate to manage our image collection process.
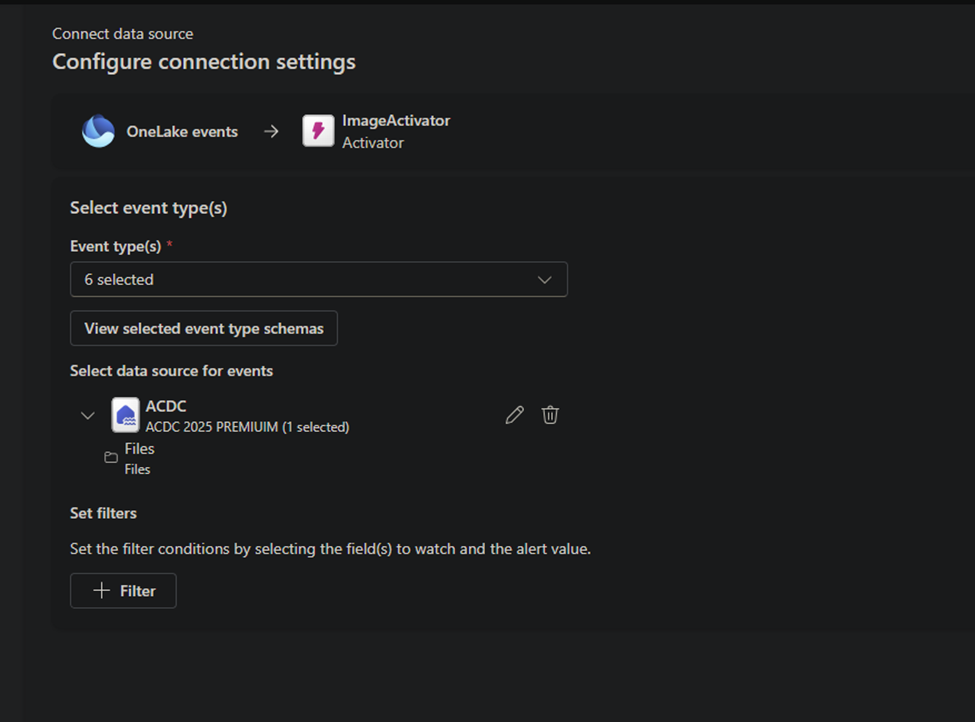
We firstly created data activator and selected our data sources, so activator knows when and where to trigger.
We configured it so it will only trigger when an image file is added to our Images folder for students.
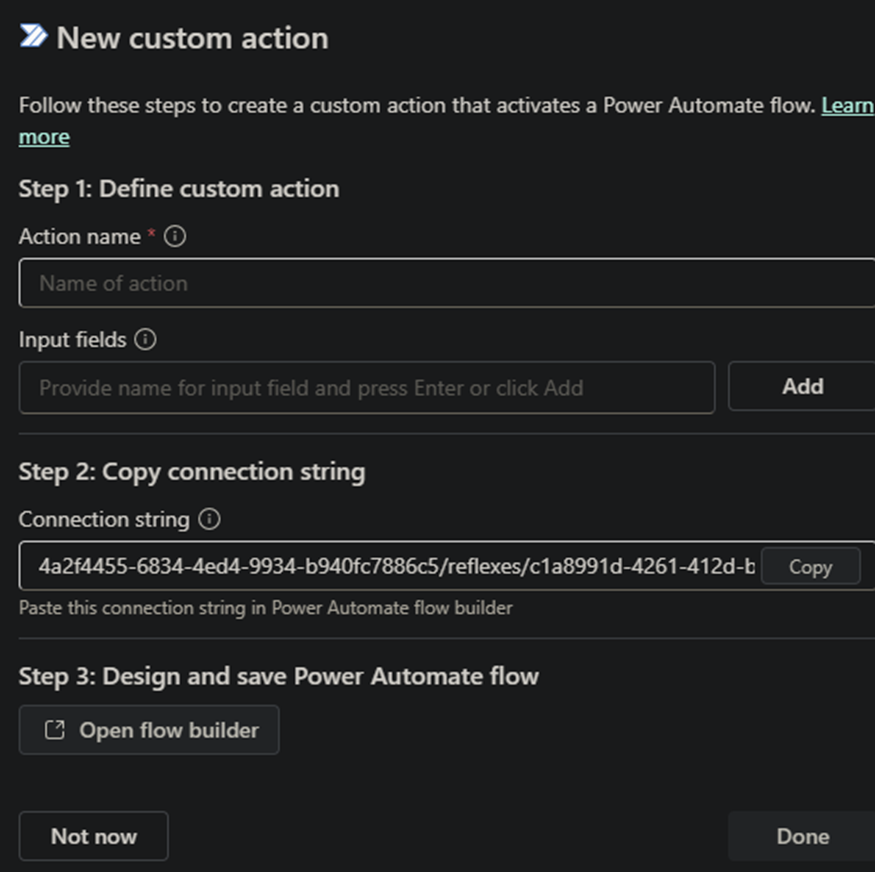
Define action and create flow to run.
Here we define an action and it gives us endpoint to be used as flow trigger. We will come back to here at last step.
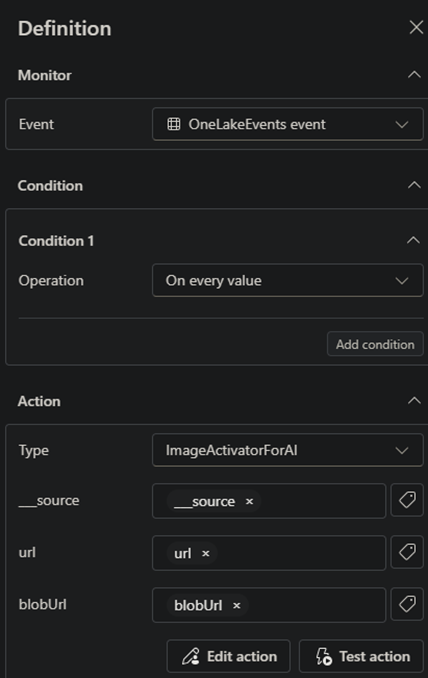
We need to create a rule to call the action we defined. This rule allow us to add additional conditions to our filter if needed, let us choose which action to call. Also we can add additional parameters to be sent to power automate flow.
And lastly our power automate flow: The endpoint we received before needs to be set for connection of trigger.
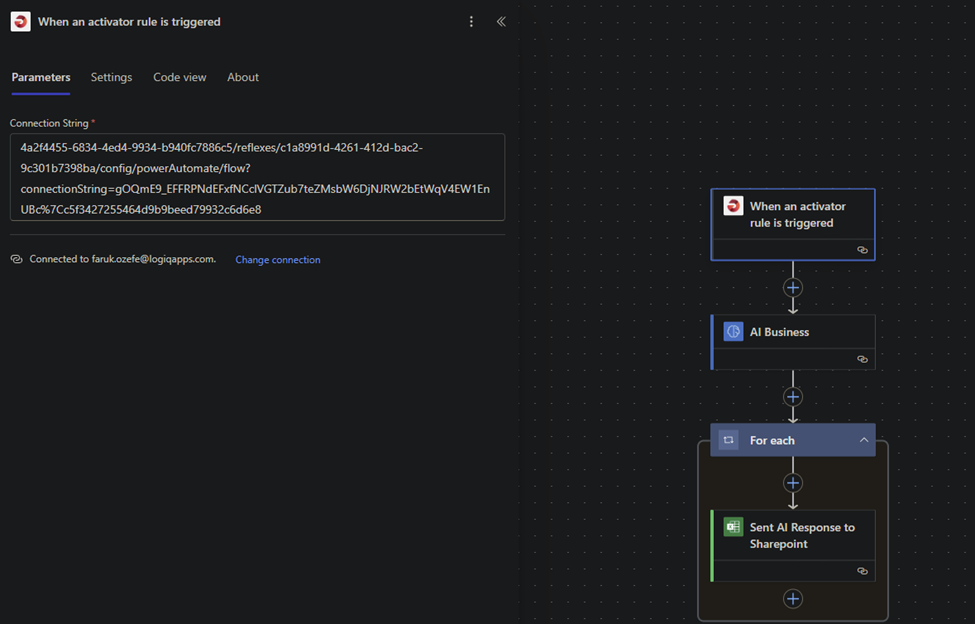
We are using power platforms ai builder to recognize the data and categorize it for further usage.
We send our response to sharepoint for further operations.

As Fabricator it is important to automate our business and keep it tidy and neat. This is the way of the fabricator.