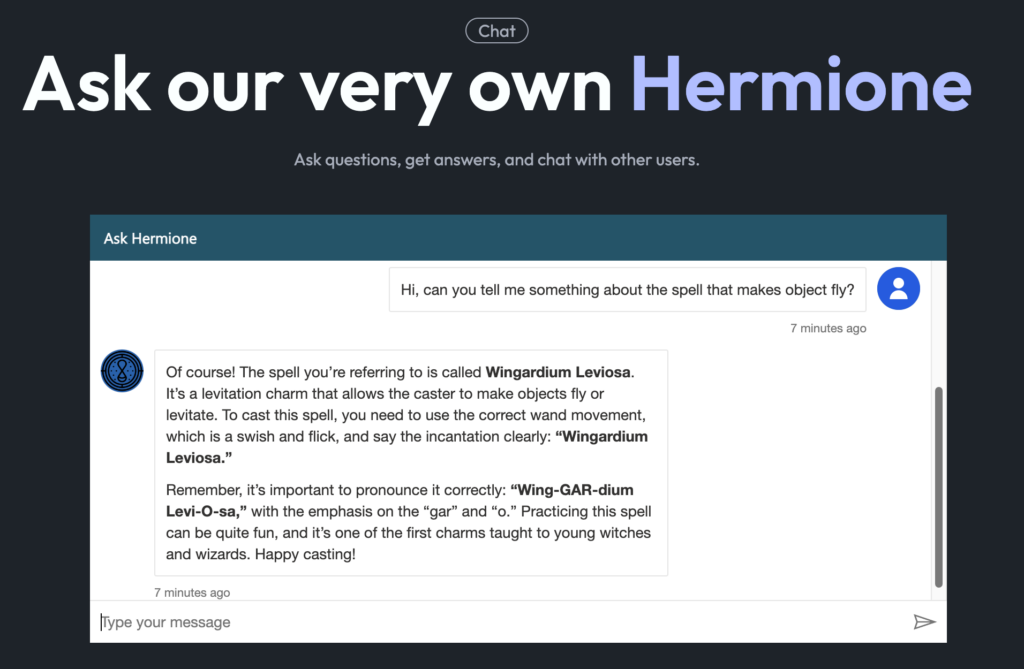
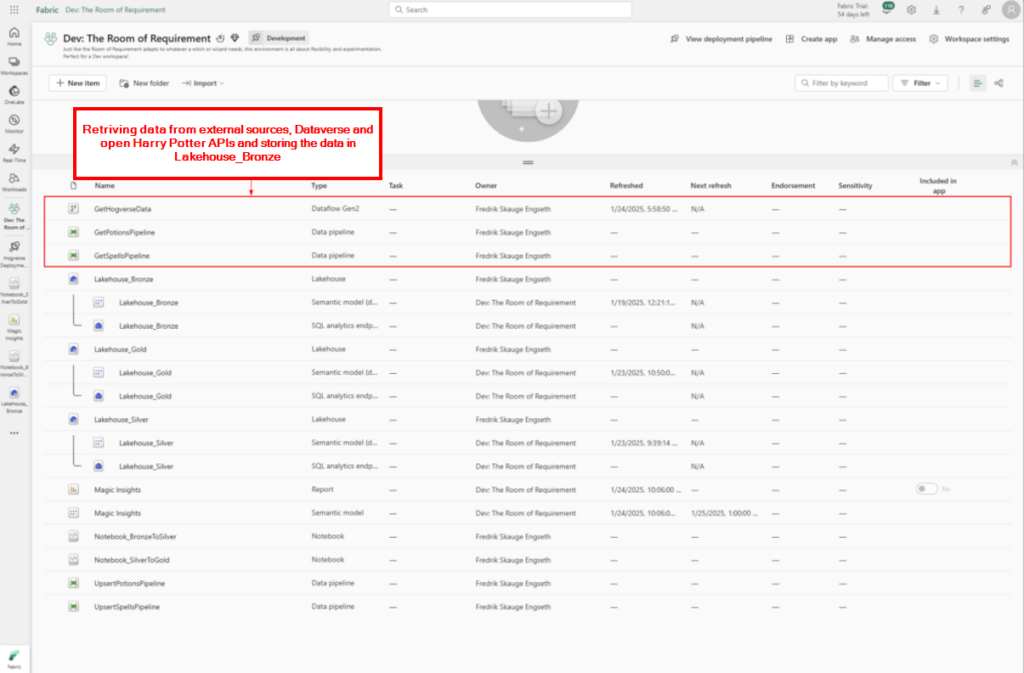
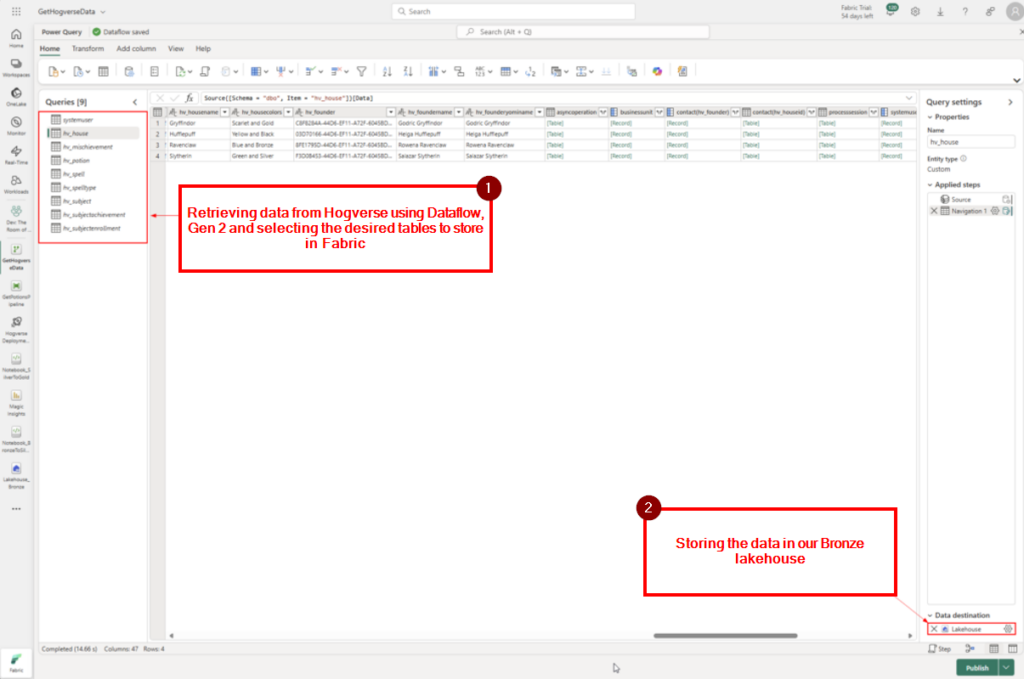
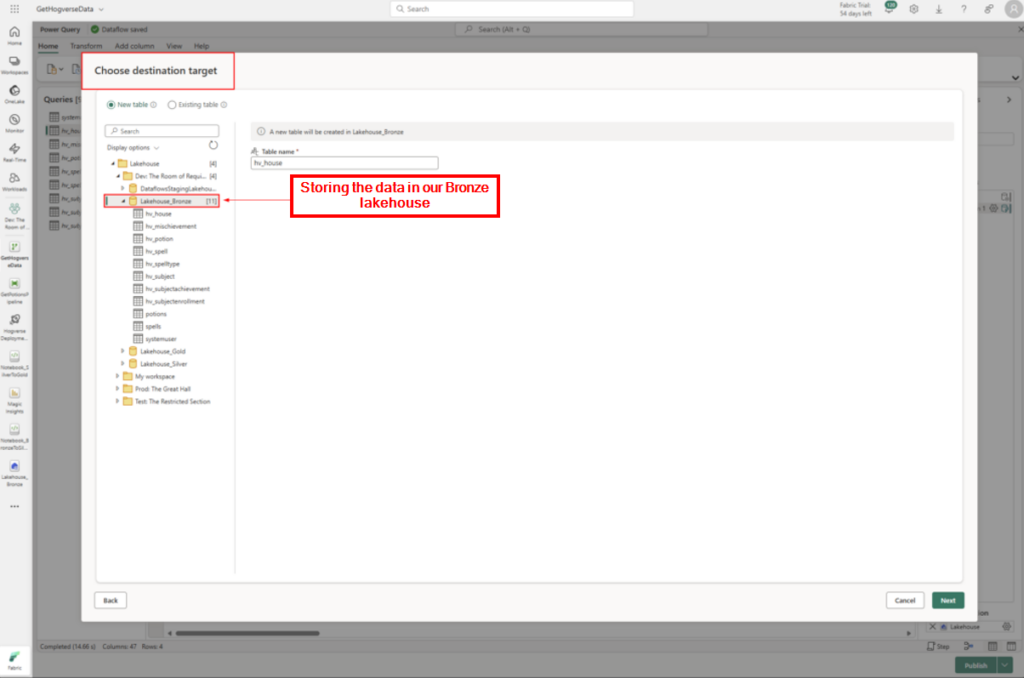
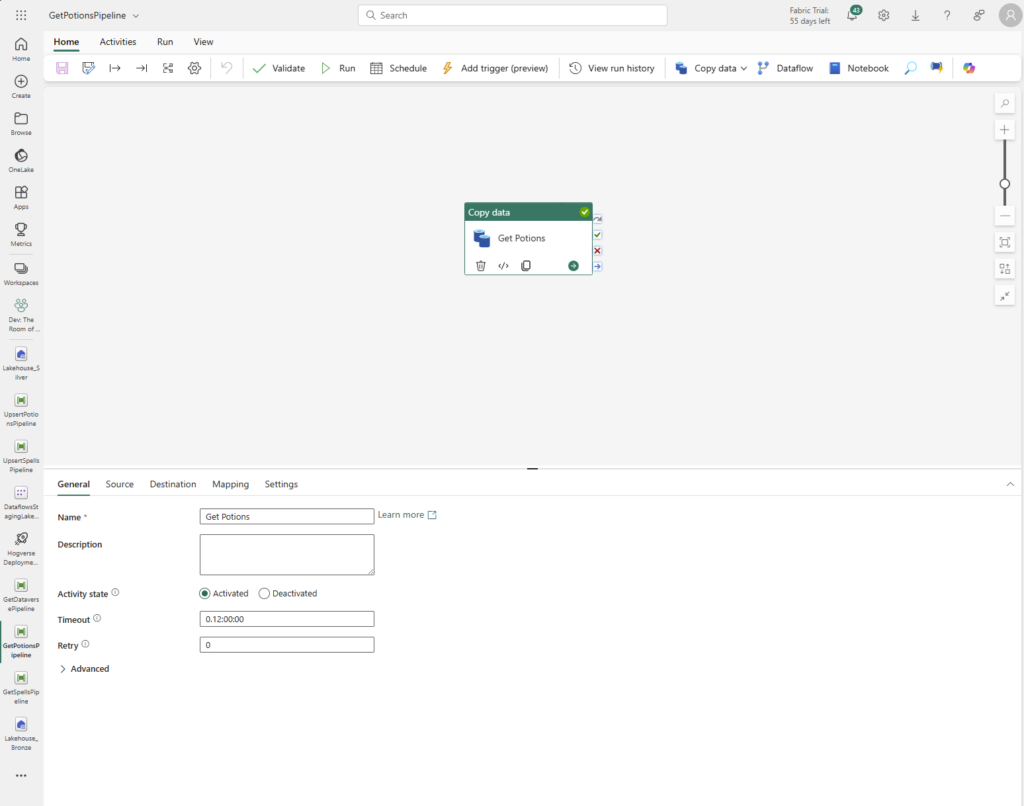
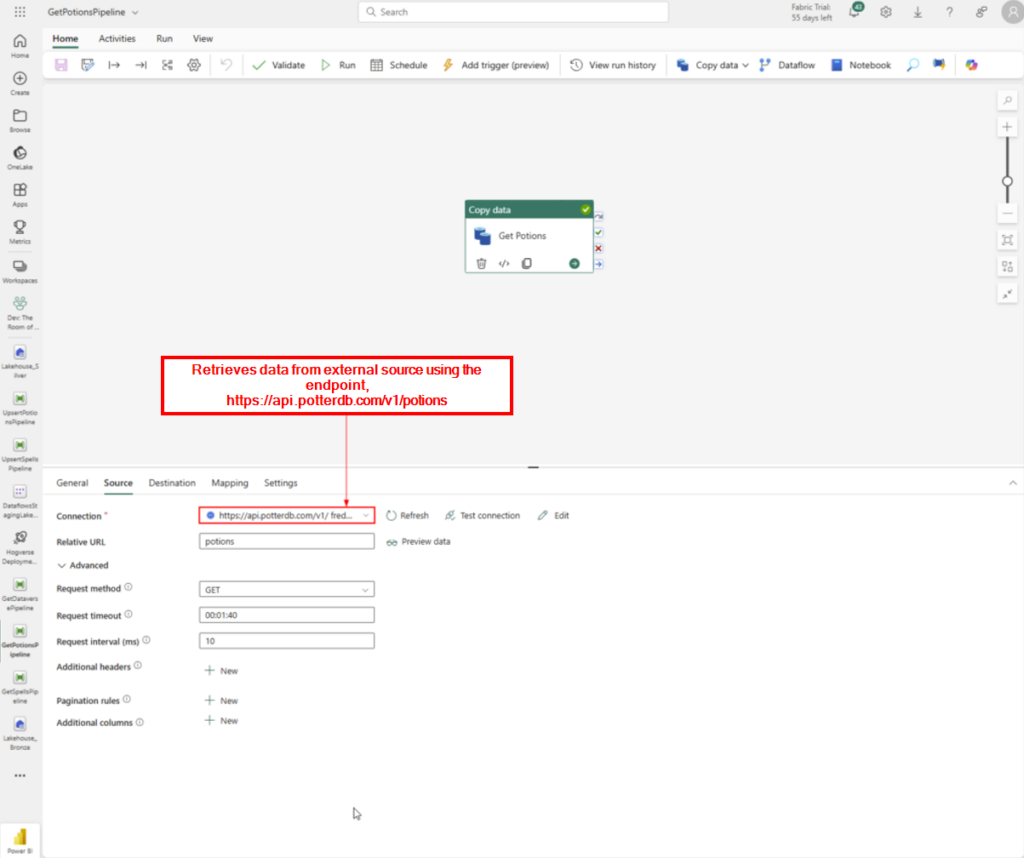
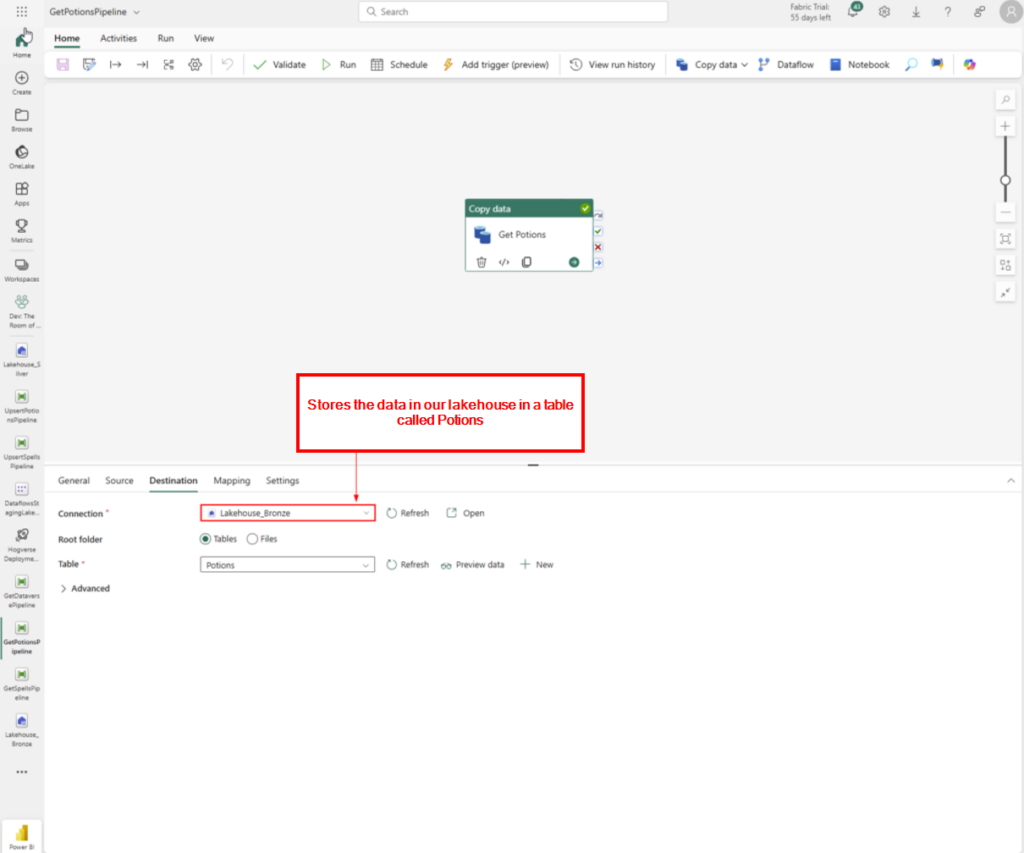
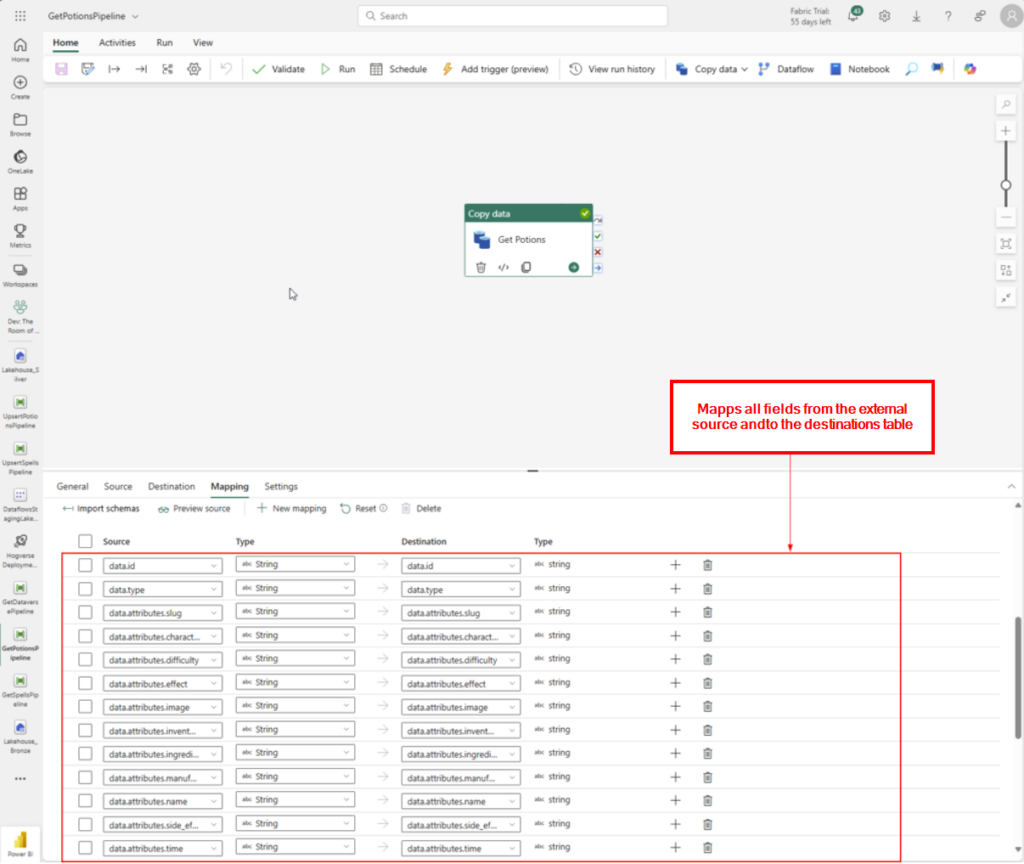
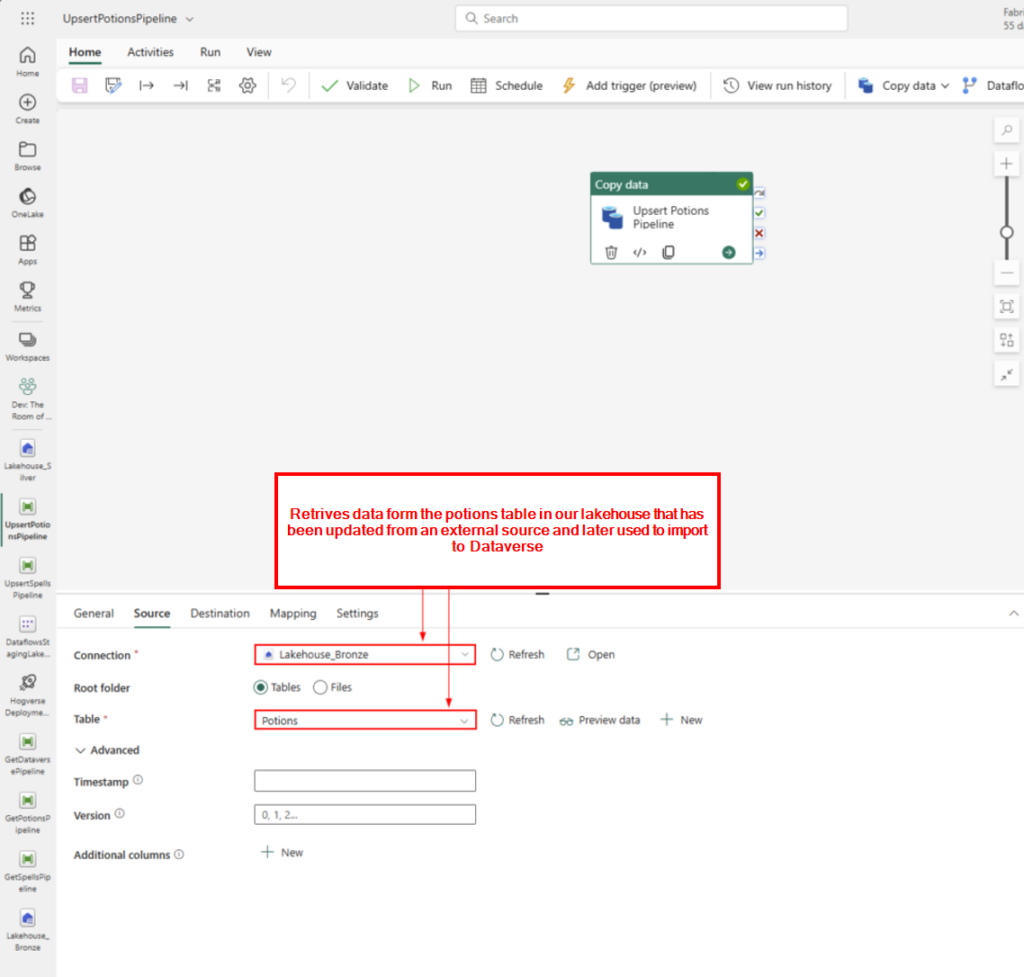
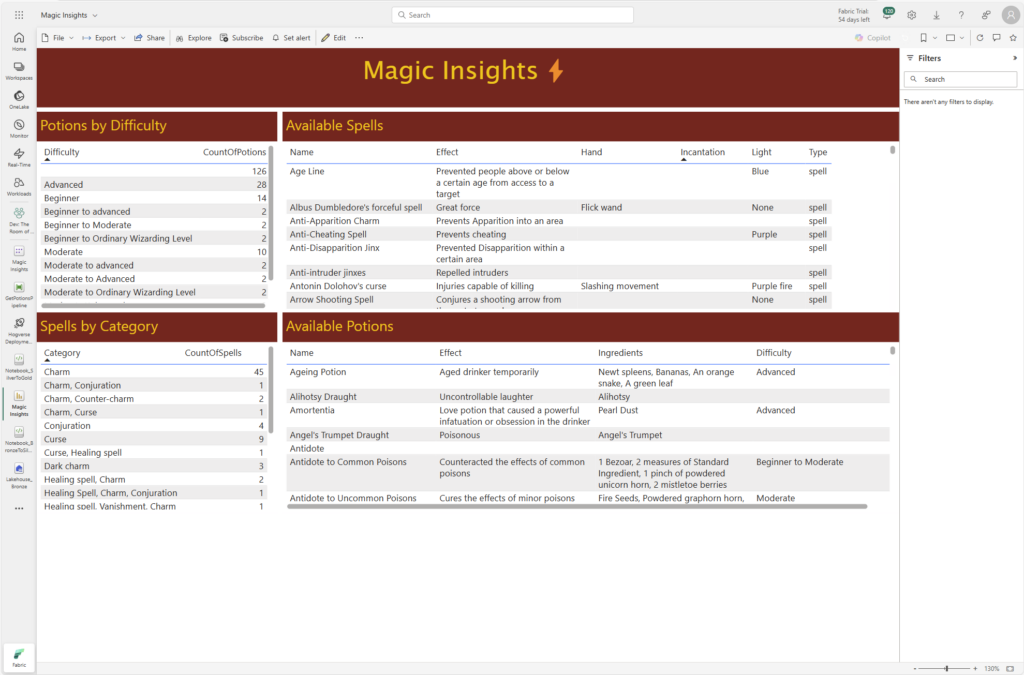
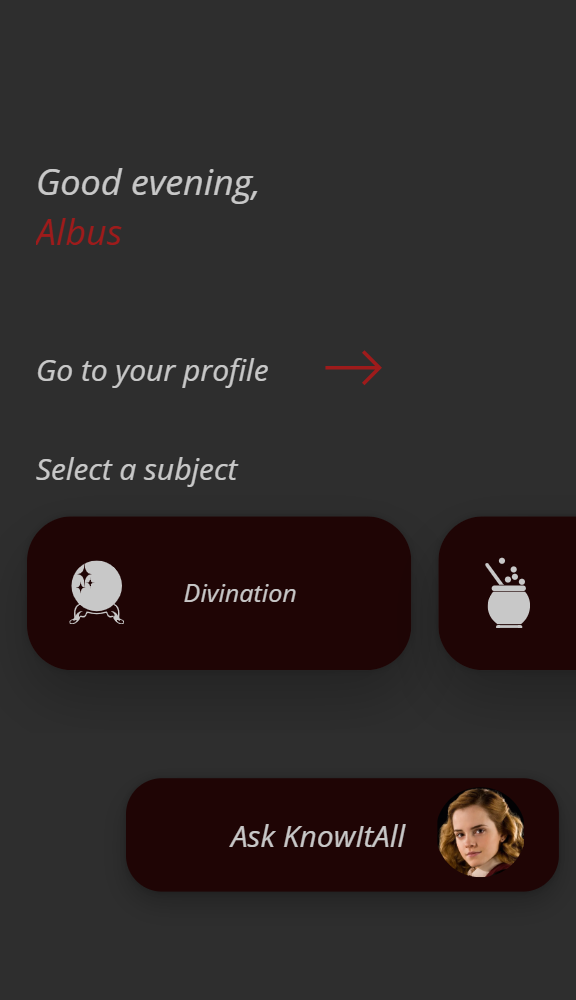
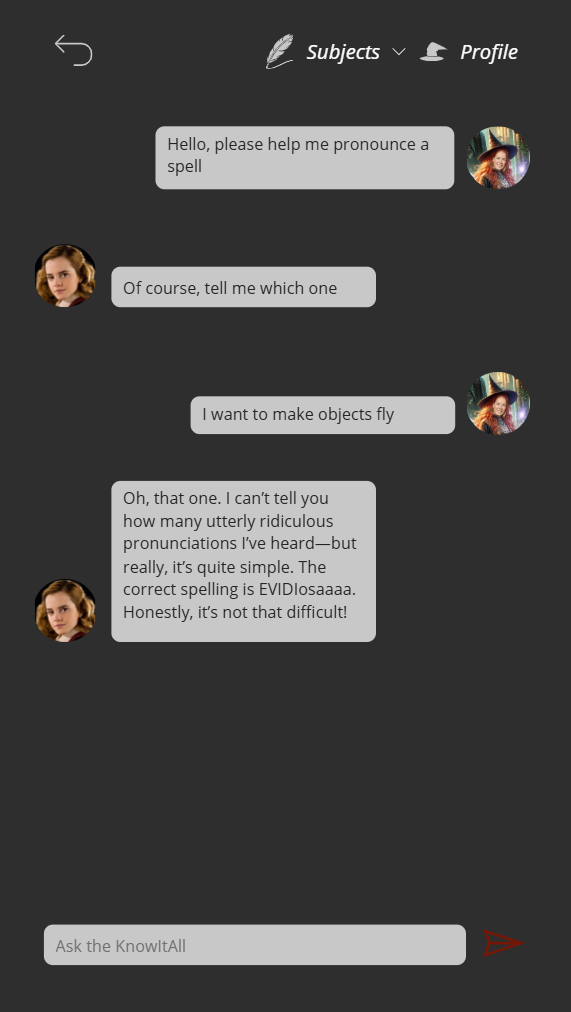
In a world of cutting-edge technology and modern SharePoint capabilities, sometimes it’s fun—and rewarding—to take a step back in time. For our quest to earn the coveted Retro Tech Badge, we decided to embrace some retro magic by implementing a nostalgic throwback: an early 2000s-style personality quiz!
The result? A delightful HTML-based quiz embedded in SharePoint that answers the all-important question: “What Jelly Bean Flavor Are You?”
Why Retro?
As part of our journey to explore deprecated or legacy technologies, we wanted to celebrate the quirks of simpler times while showing off some classic techniques that still work today. Think back to those vibrant, personality-packed quizzes from the early 2000s—quirky, colorful, and full of charm. By creating one of these in SharePoint, we combined a blast from the past with modern-day SharePoint flexibility.
Code:
<!DOCTYPE html>
<html>
<head>
<title>What Jelly Bean Flavor Are You?</title>
</head>
<body style="font-family: Arial, sans-serif; text-align: center; margin: 20px; background-color: #fef5e7; color: #5c3d2e;">
<h1><font size="5">What Jelly Bean Flavor Are You?</font></h1>
<p>Answer the questions to discover your inner jelly bean flavor!</p>
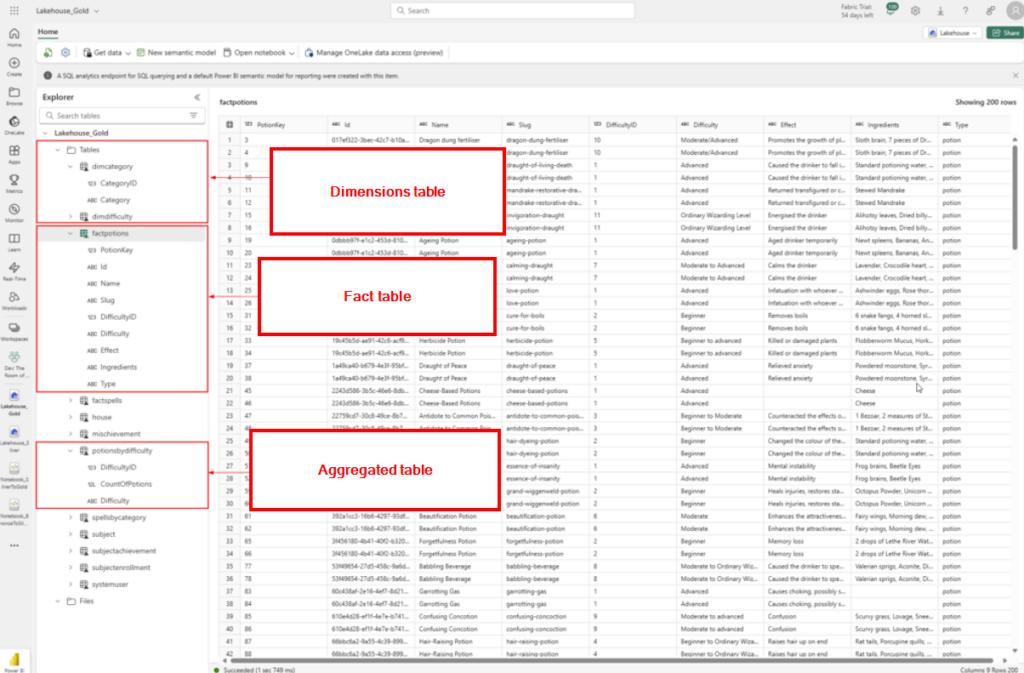
<table align="center" style="margin-top: 20px;">
<tr>
<td>
<p><b>1. What is your favorite time of day?</b></p>
<input type="radio" name="q1" value="Coconut"> Morning<br>
<input type="radio" name="q1" value="Watermelon"> Afternoon<br>
<input type="radio" name="q1" value="Chocolate"> Evening<br>
<input type="radio" name="q1" value="Cinnamon"> Late Night<br>
</td>
</tr>
<tr>
<td>
<p><b>2. What is your go-to weekend activity?</b></p>
<input type="radio" name="q2" value="Cinnamon"> Party with friends<br>
<input type="radio" name="q2" value="Chocolate"> Movie night<br>
<input type="radio" name="q2" value="Coconut"> Hiking or outdoors<br>
<input type="radio" name="q2" value="Watermelon"> Relaxing at home<br>
</td>
</tr>
<tr>
<td>
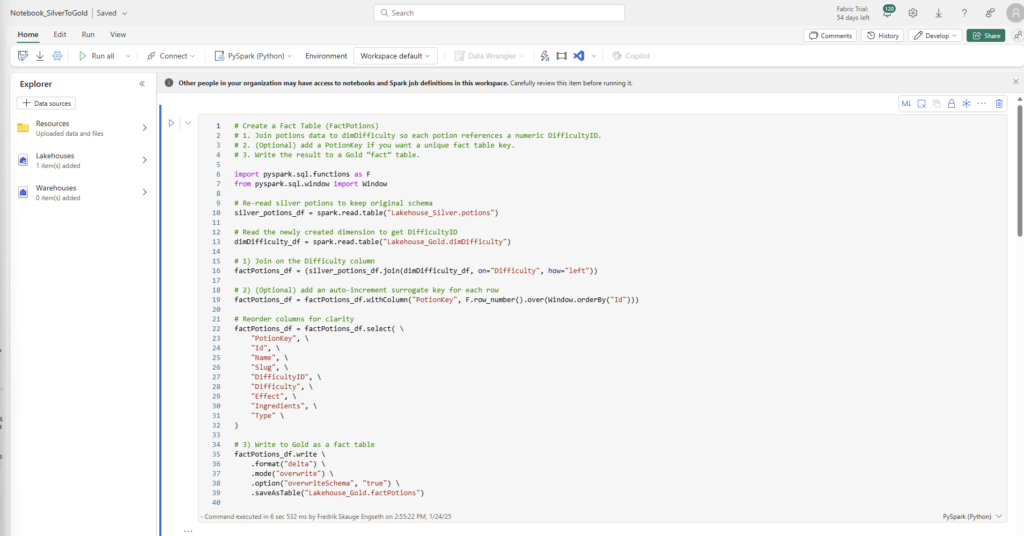
<p><b>3. Pick a color:</b></p>
<input type="radio" name="q3" value="Watermelon"> Green<br>
<input type="radio" name="q3" value="Coconut"> White<br>
<input type="radio" name="q3" value="Cinnamon"> Red<br>
<input type="radio" name="q3" value="Chocolate"> Brown<br>
</td>
</tr>
</table>
<button style="padding: 10px 20px; margin-top: 20px; background-color: #ffcc00; color: #5c3d2e; border: none; cursor: pointer;" onclick="showResult()">Find Out!</button>
<p id="result" style="margin-top: 30px; font-weight: bold;"></p>
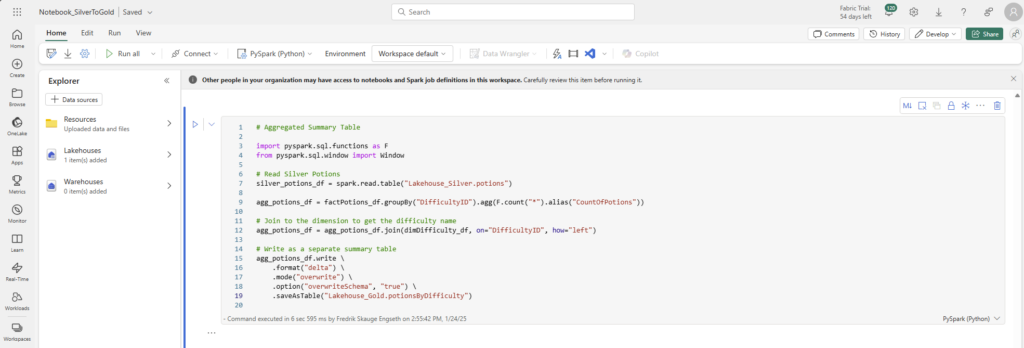
<script>
function showResult() {
var answers = {};
for (var i = 1; i <= 3; i++) {
var radios = document.getElementsByName('q' + i);
for (var j = 0; j < radios.length; j++) {
if (radios[j].checked) {
var flavor = radios[j].value;
answers[flavor] = (answers[flavor] || 0) + 1;
}
}
}
var topFlavor = null;
var maxCount = 0;
for (var flavor in answers) {
if (answers[flavor] > maxCount) {
topFlavor = flavor;
maxCount = answers[flavor];
}
}
var resultDiv = document.getElementById('result');
if (topFlavor) {
resultDiv.innerHTML = '<font size="4">You are <b>' + topFlavor + '</b>! Sweet and full of flavor!</font>';
} else {
resultDiv.innerHTML = '<font size="4">Please answer all the questions to get your flavor!</font>';
}
}
</script>
</body>
</html>
What Makes This Retro?
- Use of
<font>Tags: Instead of modern CSS, the<font>tag is used for styling, which has been deprecated for years. - Inline Styles: Styling is applied directly to elements instead of through a
<style>block or external stylesheet. - Table-Based Layout: Questions are wrapped in a
<table>for structure, which was a common practice in the early days of web development before<div>-based layouts became standard. - Direct DOM Manipulation: Instead of modern
querySelector, it usesdocument.getElementsByNamefor gathering inputs. - Global JavaScript Functions: Functions like
showResultare globally scoped, which was common before modern practices like modules or IIFEs (Immediately Invoked Function Expressions).
Badge-Claim Justification
- The code directly incorporates deprecated HTML elements and practices.
- The use of inline styles and table-based layout aligns with retro web development techniques.
- It adds charm and nostalgia to our SharePoint implementation while meeting the criteria for retro tech.