When building applications that leverage AI technologies, monitoring performance is crucial for ensuring that the system operates smoothly. One powerful tool for this is Azure Application Insights, which allows us to collect, analyze, and visualize telemetry data in a way that provides both technical insights and an understanding of user interactions.
Azure Application Insights is an Application Performance Management (APM) service that helps you monitor your applications in real-time.
In this post, we’ll show how we used Azure Application Insights to create dashboards that track key metrics for our Sorting Hat, focusing on GPT prompt and response tokens, response times, user interactions, and language distribution. These insights can help us optimize the performance of our AI model, identify trends, and make data-driven decisions.
Let’s break down the key metrics that we are tracking:
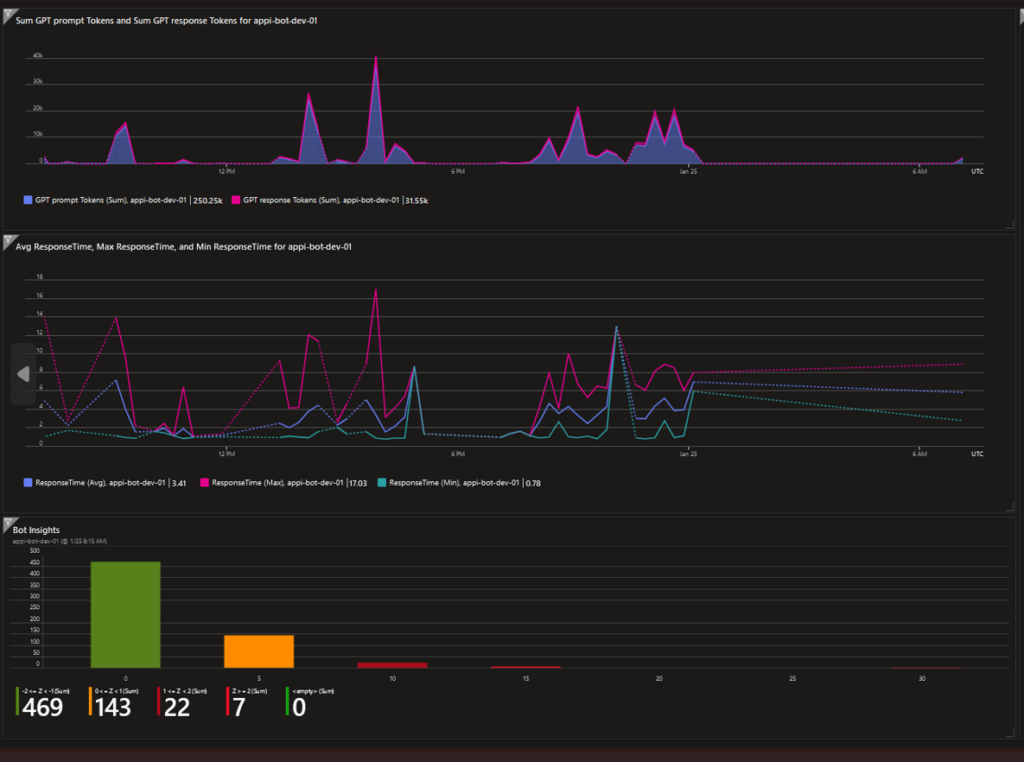
- GPT Prompt & Response Tokens: The number of tokens used in GPT prompts and responses can have a significant impact on performance and cost.
- Average, Minimum, and Maximum Response Time: These metrics provide an overall view of how long the application takes to respond.
- Response Time Distribution: This helps us understand how response times vary across different requests.
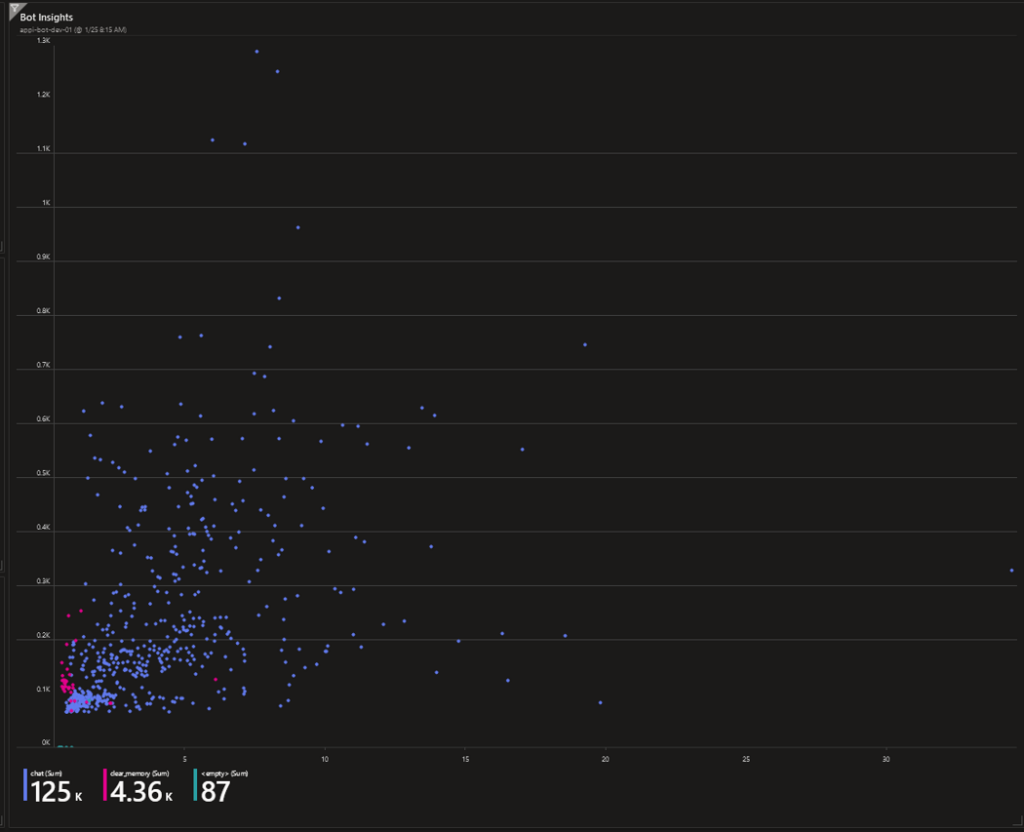
- Response Time vs. Tokens: This allows us to correlate response time with the number of tokens used.
- Active User Chats: Monitoring how many users are actively chatting with the AI at any given moment helps gauge the engagement level.
- Language Distribution: When application supports multiple languages, this metric helps to track which languages are being used most often.
- Average, Minimum, Maximum and Standard Deviation response time in last 30 days: These metrics help ensure that the application performs optimally and allow us to identify any unusual behavior or potential bottlenecks.